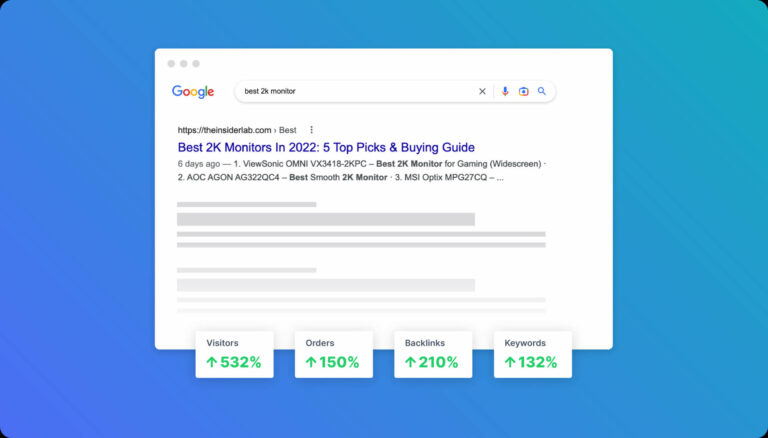
Technical SEO: How to optimize the Technical SEO in 2023

Is it true that when embarking on the journey of website SEO, the 3 main tasks you always need to perform throughout are: Technical SEO, Onpage SEO, and Offpage SEO. In particular, Technical SEO is a very important step in the entire SEO process.
However, how to properly perform Technical SEO? No one detailed how and why you need to do it. But you have found your answer today!
This is the newest and most complete guide to Technical SEO. In this guide, I’ll help you learn all about:
- Crawl and index
- XML sitemaps
- Duplicate content
- Structured data
- Hreflang
- Lots more
And more. So if you want to make sure your Technical SEO is up to speed then start with my guide now!
Let’s go!
Basic information about Technical SEO you need to know
What is Technical SEO?
Technical SEO is the process that refers to website and server optimization, which helps search engines crawl and index websites more efficiently (which improves rankings).
Technical SEO checklist
As I said, “Technical SEO” is not just crawling and indexing.
To improve technical website optimization, it is necessary to take into account:
- Keyword-focused H1, title + description in the controller
- Site architecture and Breadcrumb navigation
- Internal linking (in the article and also sidebar widgets)
- Basic schema markup
- XML sitemap (or index of sitemaps) to submit to GSC
- Redis to cache database queries
- Cloudflare Page Rules to cache the front end
- Javascript
- URL structure
- Thin content
- Duplicate content
- Hreflang
- Canonical tags
- 404 pages
- 301 redirects
And I’ll cover all of the above (and more) in the rest of this guide.
How to do Technical SEO
Site Structure and Navigation
In my experience, setting up a website structure is the “First Step” of any Technical SEO strategy. Because there are a lot of crawling and indexing issues that happen due to a poorly designed website structure. Therefore, if you follow this step correctly, you do not need to worry about Google indexing all the pages on your website.
Second, site structure affects everything else you do to optimize your website from URLs to sitemaps and your use of robots.txt to block search engines from certain pages.
The bottom line here you need to always keep in mind: Technical SEO becomes easier than ever when the website has a strong structure.
If you find out that your website didn’t have a probability structure then you should reach out to website redesign services and let them help you.
Without saying too much, I give you the steps to follow:
Use a flat website structure (flat structure), organized
Website structure is how all the pages on a website are organized.
In general, you should have a “Flat” structure. In other words: all pages on your website should be only a few links away from each other.
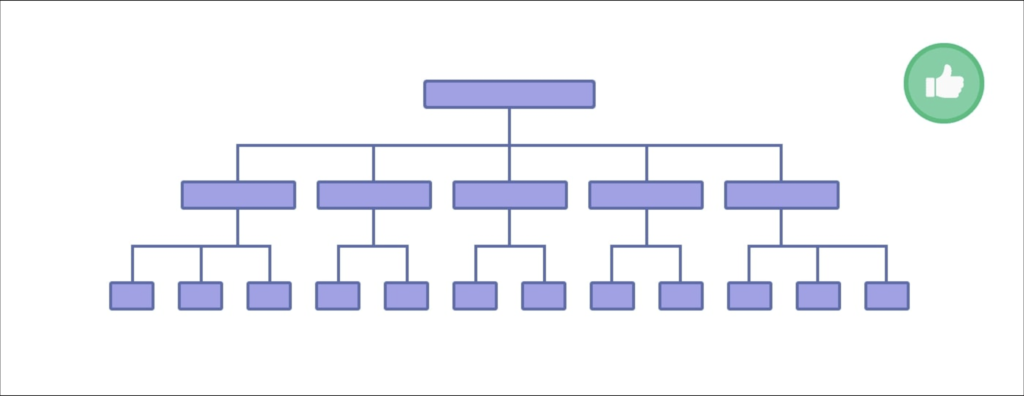
Flat structure, making it easy for Google and other search engines to crawl 100% of the pages on your website. This is not a big deal for blogs or local store websites. But for an e-commerce website with 250,000 product pages, a Flat structure is the most important thing.
You also want your website structure to be super organized.
In other words, you don’t want to structure your website like this:
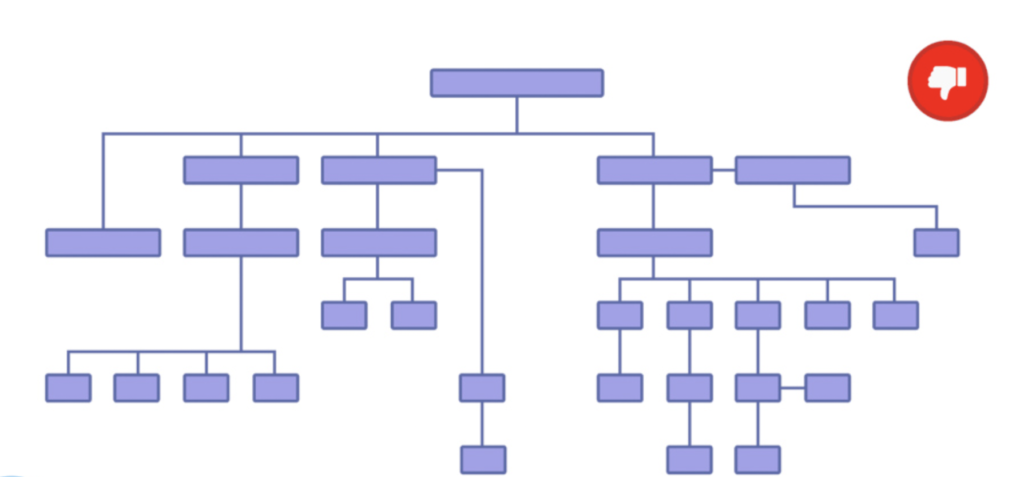
This messy structure often creates “orphan pages” (pages that don’t have any internal links pointing to them).
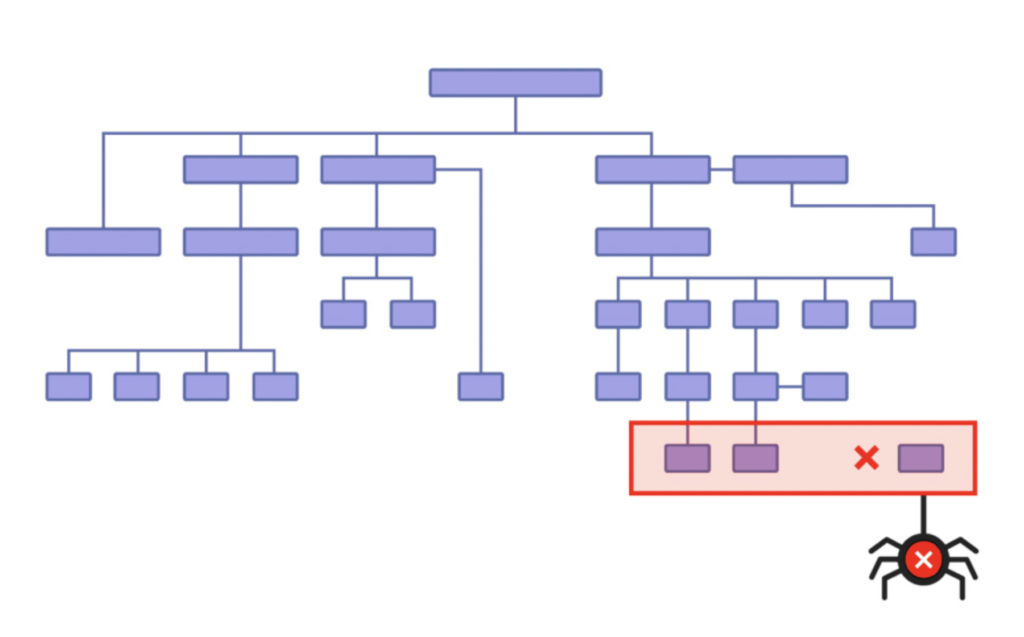
It also makes it difficult to identify and fix indexing problems.
You can use Ahrefs “Site Audit” feature to get an overview of your site structure
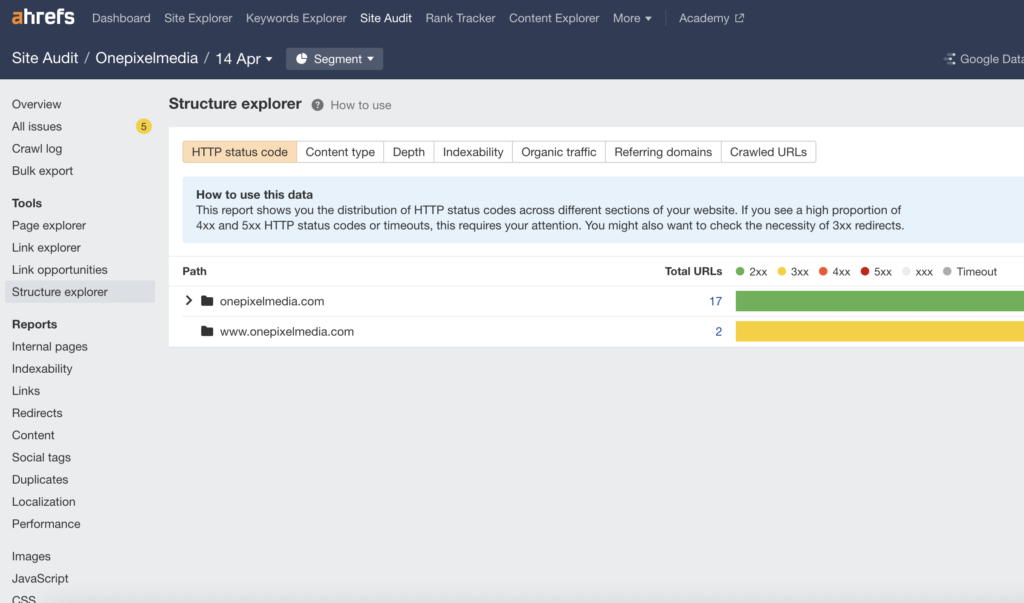
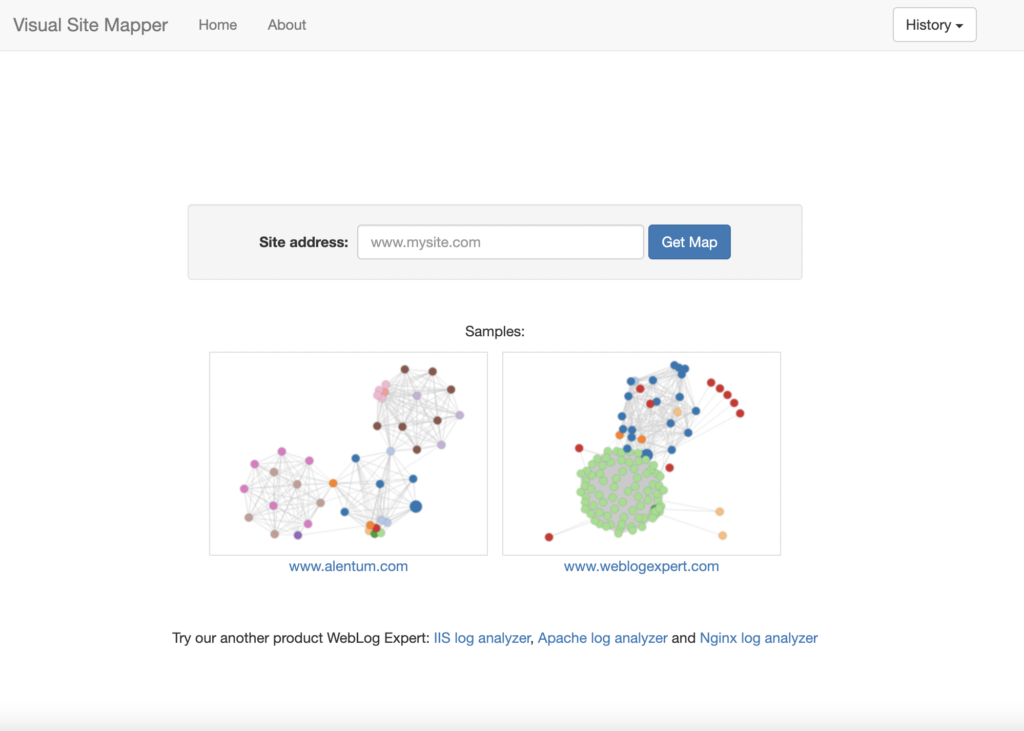
This is helpful. But it is not the deciding factor for all of your website. For a more visual look at how pages are linked together, see Visual Site Mapper.
It’s a free tool that gives you an interactive view of your website’s structure.
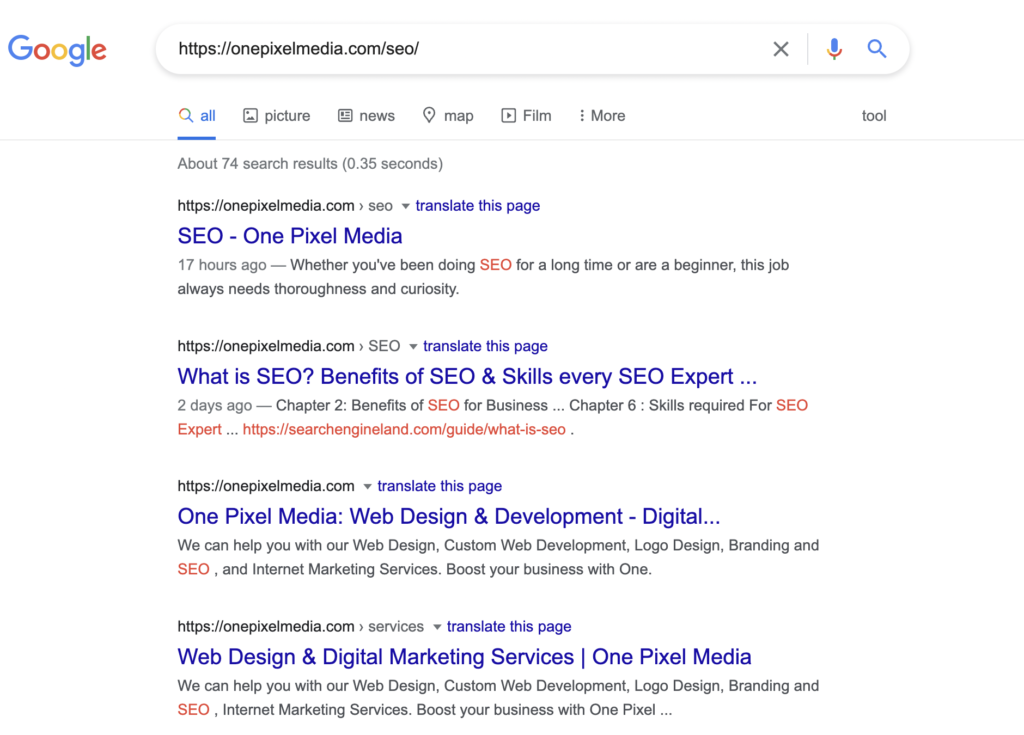
Consistent URL structure
There is no need to think too much about URL structure if you run a small website (like a blog). That said: URLs need to follow a consistent, logical structure. This really helps users understand where they are on your website.
And placing pages under different categories gives Google more context about each page in that category.
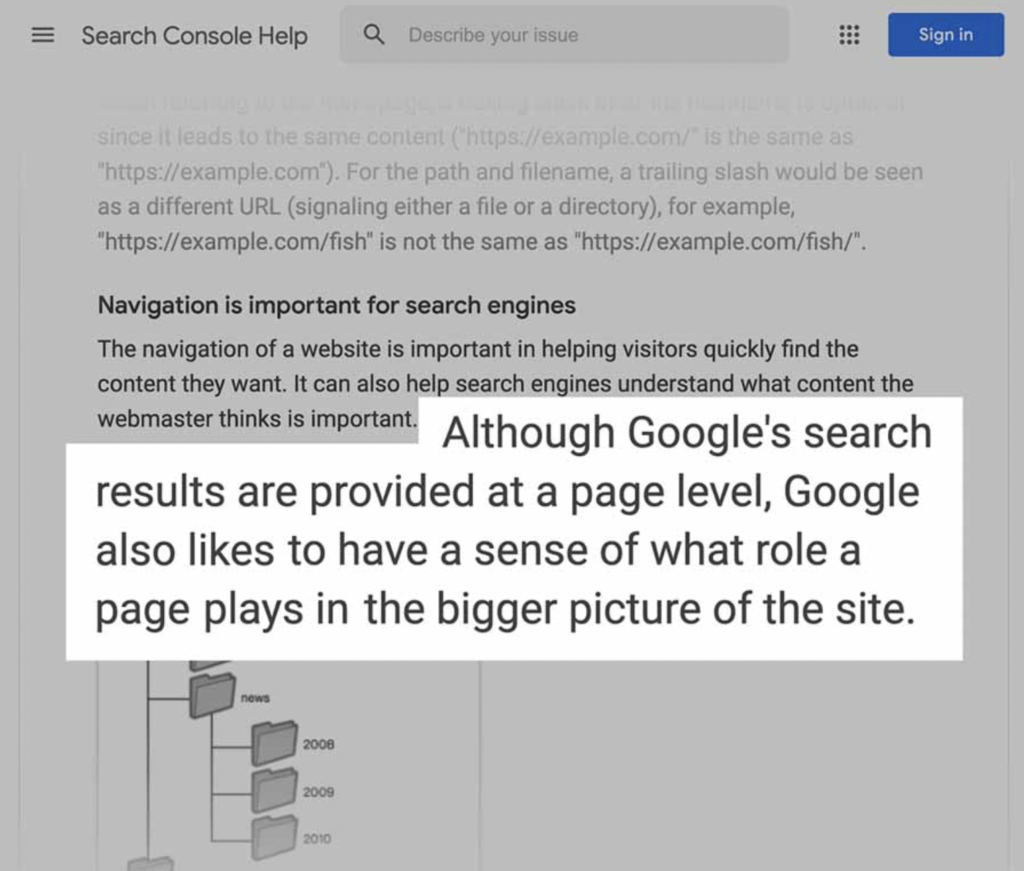
For example, all of One Pixel Media’s SEO pages include a “/SEO/” directory to let Google know that all of these pages fall under the “SEO” category.
Breadcrumbs Navigation
It’s no secret that Breadcrumbs Navigation is super SEO friendly. Because breadcrumbs automatically add internal links to categories and subpages on your website.

This helps strengthen the structure of your website. Not to mention the fact that Google has turned URLs into breadcrumb-style navigation in the SERPs.
So I strongly recommend using Breadcrumbs Navigation.
Crawl, Render, and Index:
In this section, I will show you how to find and fix crawl errors and how to send search engine indexes to the deep pages of your website.
Ways to help you index
Method 1: Coverage Report
This way, you will first go to “Coverage Report” in Google Search Console. This report tells you if Google can’t index or fully display the pages you want to index.
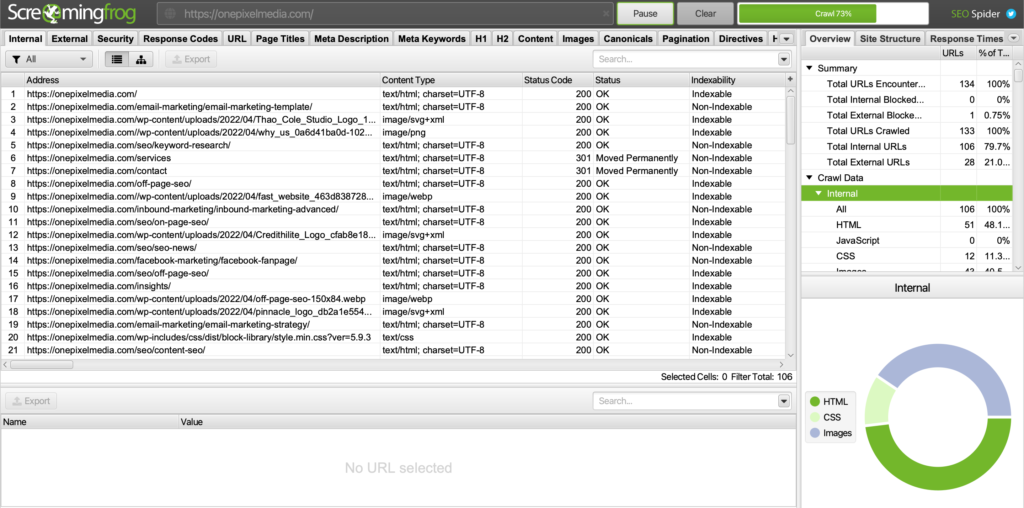
Method 2: Screaming Frog
Screaming Frog is the most famous crawler in the world because it’s really good and get the job done. So, after you’ve fixed any issues in your Coverage Report, I recommend running the entire crawl with Screaming Frog.
Method 3: Ahrefs Site Audit
Ahrefs has a tool called SEO site audit
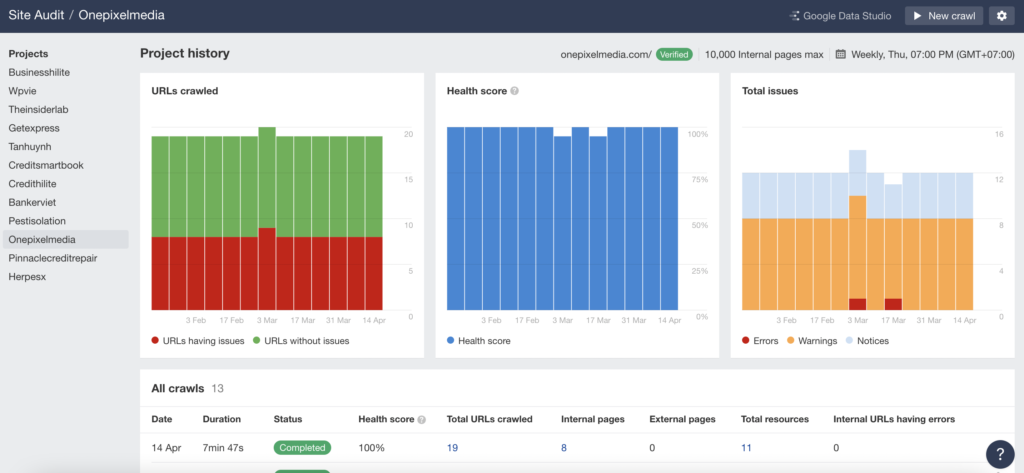
What I like most about this feature is that you get information about:
- The overall Technical SEO status of your website.
- Page load speed on the entire website.
- Problems with the website’s HTML tags.
Each of these 3 tools has pros and cons. So, if you run a large website with more than 10k pages, I recommend using all three of these approaches.
Internal Link to “Deep” Pages
Most people don’t have any problem setting up the homepage index. It is these “Deep” Pages (pages are some links from the homepage) that tend to cause problems.
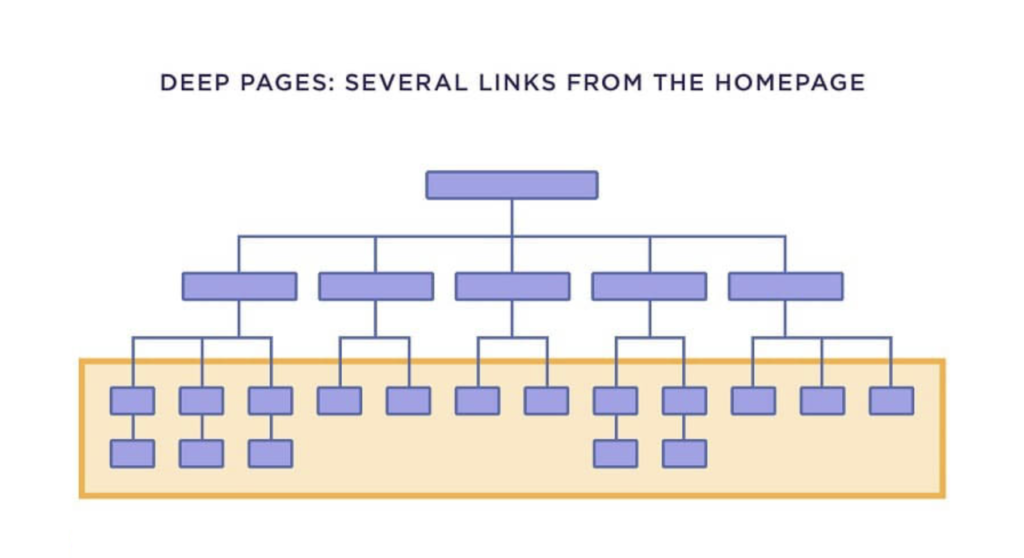
A flat construct often prevents these problems from happening in the first place. Therefore, your “Deep” Pages will be only 3-4 clicks from the homepage. Either way, if there’s a particular “Deep” Page or set of pages that you want to index, nothing beats good internal linking to that page. More specifically, if the page that is linking is authoritative and always crawled.
Using XML Sitemap
Do you always ask: With the priority of mobile indexing and AMP, does Google still need XML sitemap to find website URLs?
In fact, a Google representative recently declared XML sitemaps the “second most important source” for URL searches.

So, if you want to double-check to make sure your sitemap is ok, go to the “Sitemaps” feature in Search Console.
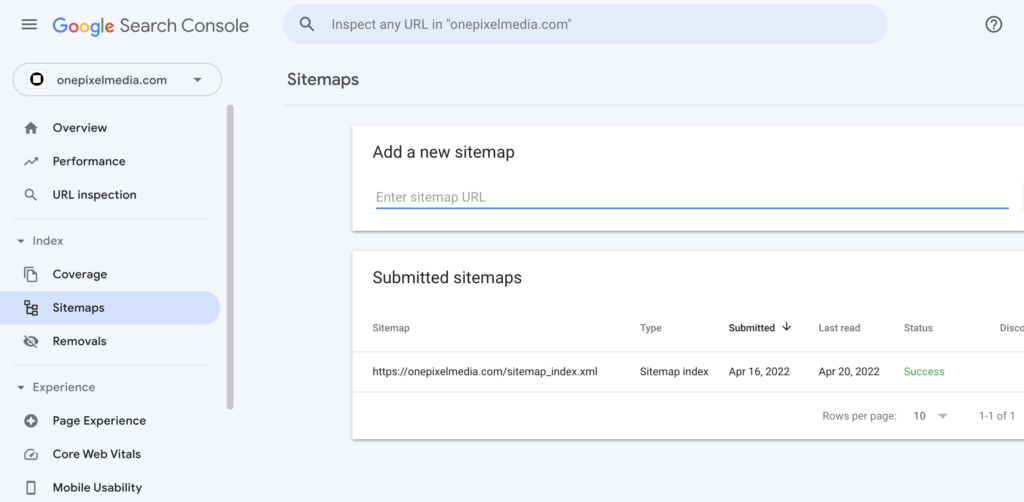
This will show you the sitemap that Google is viewing for your website.
Google Search Console “Checking”
Is a URL on your website not indexed?
GSC’s Check feature can help you dig into everything. It not only shows why a page is not indexed or already indexed:
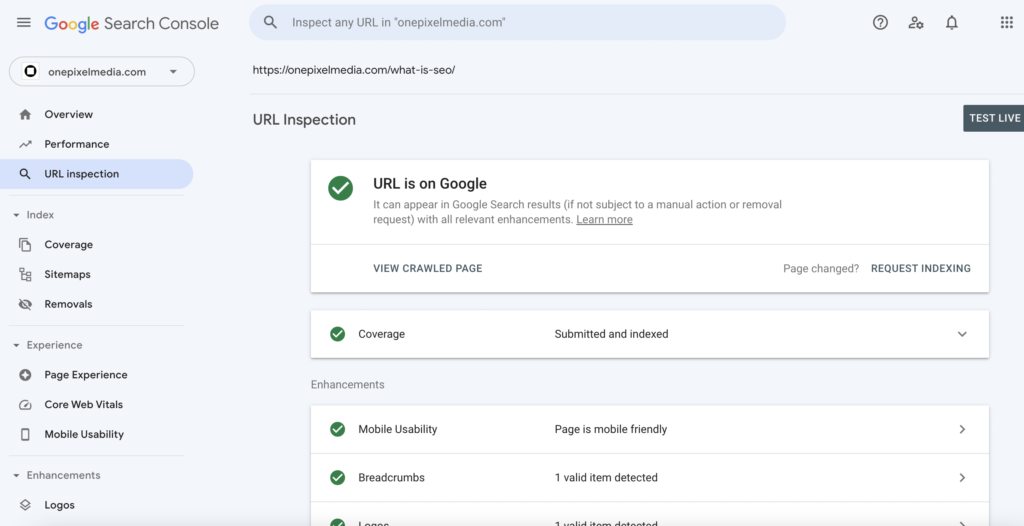
This way, you can double-check that Google can crawl and index 100% of the content on that page.
Thin and Duplicate Content
If you write unique, original content for every page on your website, you probably don’t need to worry about duplicate content. But, duplicate content can appear on any website. Especially if your CMS has created multiple versions of the same page on different URLs. And in this chapter, I’ll show you how to proactively fix duplicate and thin content issues on your website.
Use SEO Audit Tool to find Duplicate Content errors
There are two GREAT tools for finding duplicate and thin content.
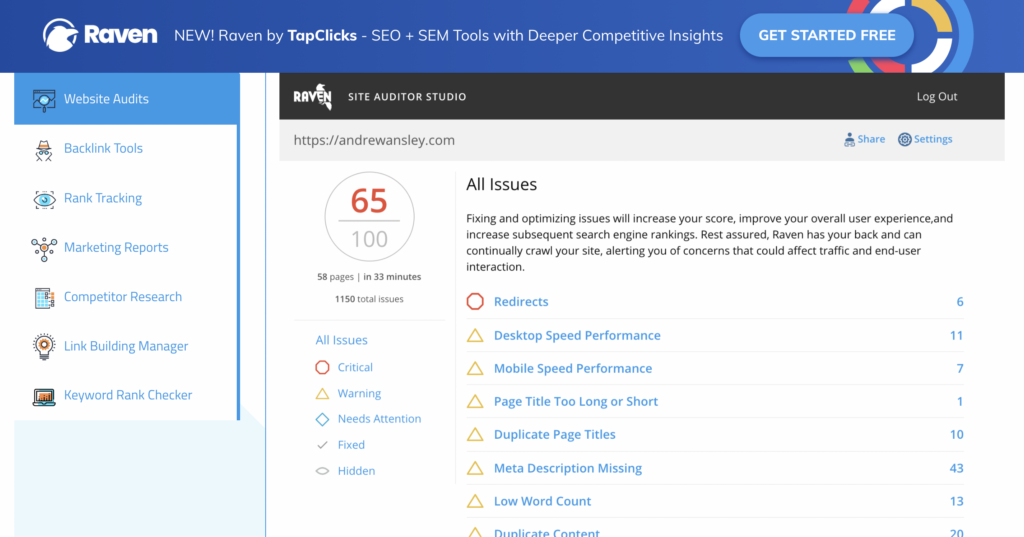
The first is Raven Tools Site Auditor.
It scans your website for duplicate content (or thin content) and tells you which pages need updating.
Next, Ahrefs’ website audit tool also has a “Content Quality” section that will show you if your website has duplicate content on some other pages.
However, these tools focus on duplicate content on your website. But in fact, you need to pay attention that “duplicate content” also includes pages that copy content from other websites. I recommend using Siteliner to find duplicate content, broken links, and more….on your website.
If you find a page on your website has a high percentage of duplicate content then you can check that URL on Copyscape and find the text that shows up on another website, search for that text in quotation marks. If Google shows your page first in the results, they will consider you the original author of that page.
Note: If someone else copies your content and puts it on their website, it's a matter of duplicating their content. Not yours. You only need to worry about the content on your website being copied (or similar) to the content from another website.
Noindex Pages with non-Unique Content
Most websites will have pages with some duplicate content. No problem. This becomes a problem when those duplicate content pages are indexed.
Solution? Add the “noindex” tag to that page. The noindex tag tells Google and other search engines not to index the page.

You can double-check that your noindex tag is set up correctly by using the “Inspect URL feature” in GSC.
Enter the URL and click on “Inspect URL feature”.
If Google is still indexing, you will see the message “URL is available to Google”. That means your noindex tag is not set up correctly.
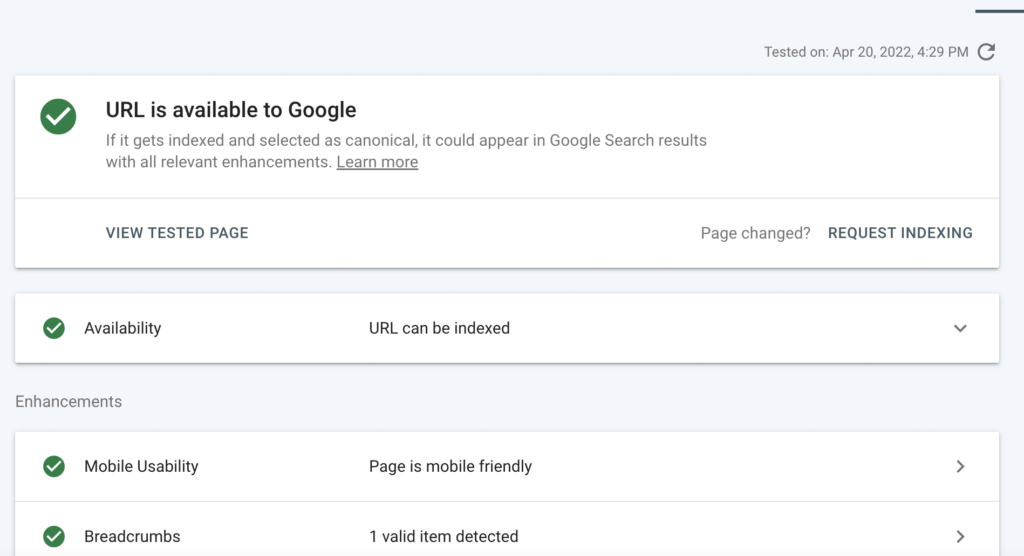
But if you see the message “Excluded by ‘noindex’ tag”, the noindex tag is doing its job.
Depending on your crawl budget, it can take days or weeks for Google to re-crawl pages you don’t want to be indexed. So I recommend you check the “Excluded” tab in the Coverage report to make sure pages that are not indexed are being removed from the index.
Note: You can also block search engine spiders from indexing the page entirely by blocking each of their crawlers in the robots.txt file.
Use Canonical URLs
Most pages with duplicate content will not have an index tag added or replace duplicate content with unique content.
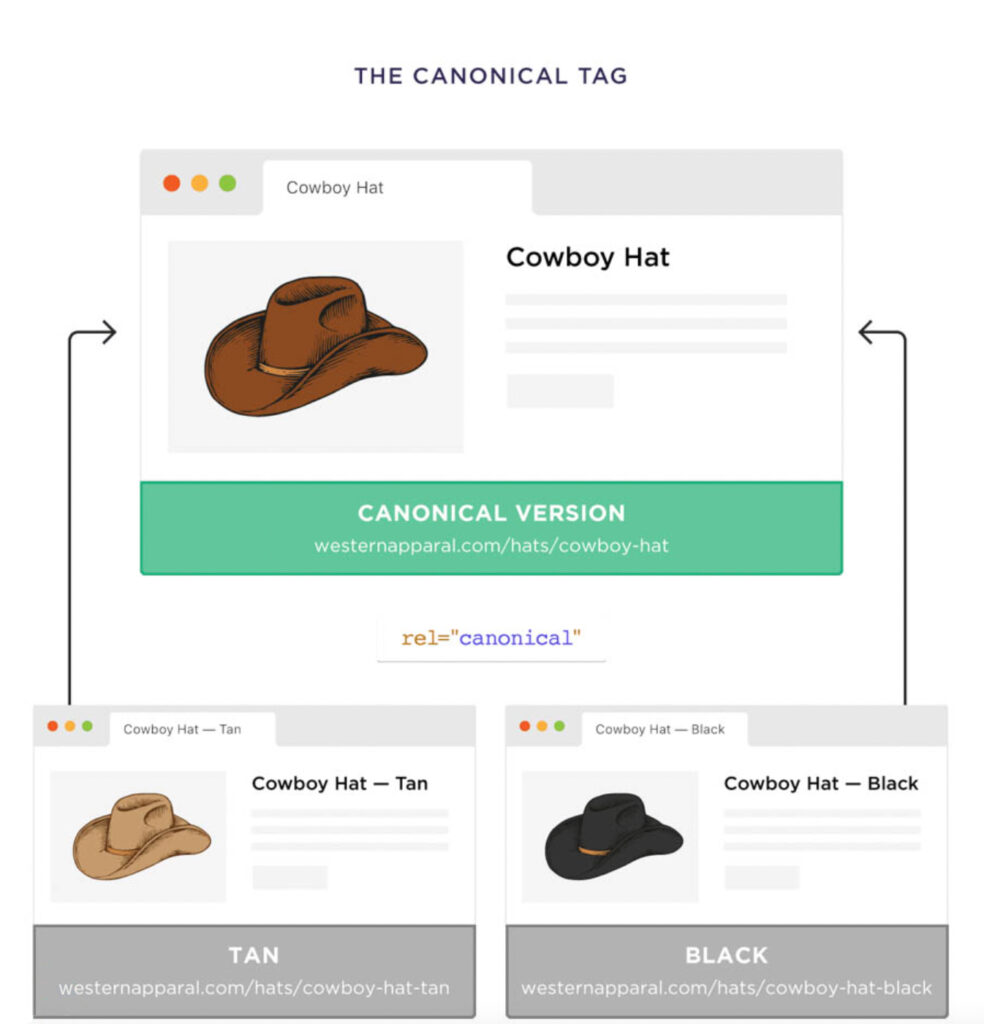
But there is another way you can use it: canonical URL. The canonical URLs are perfect for pages with very similar content on them…with slight differences between pages.
Example: Let’s say you run an e-commerce website that sells hats, a product page is indexed for cowboy hats.
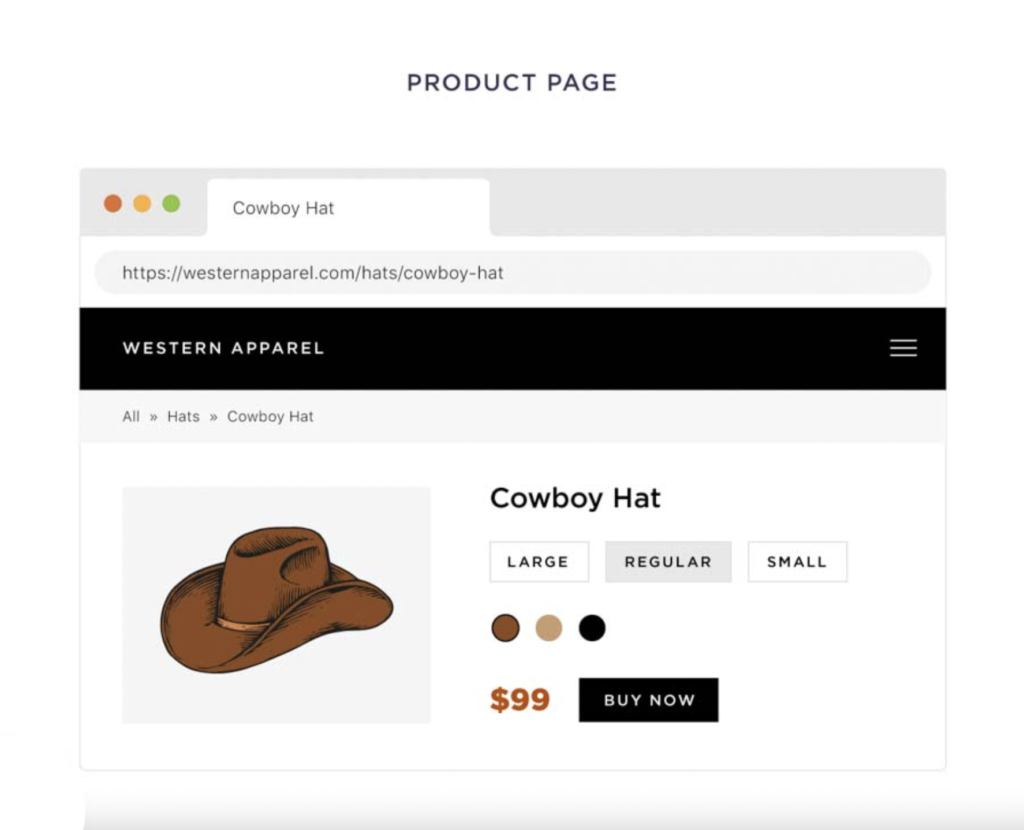
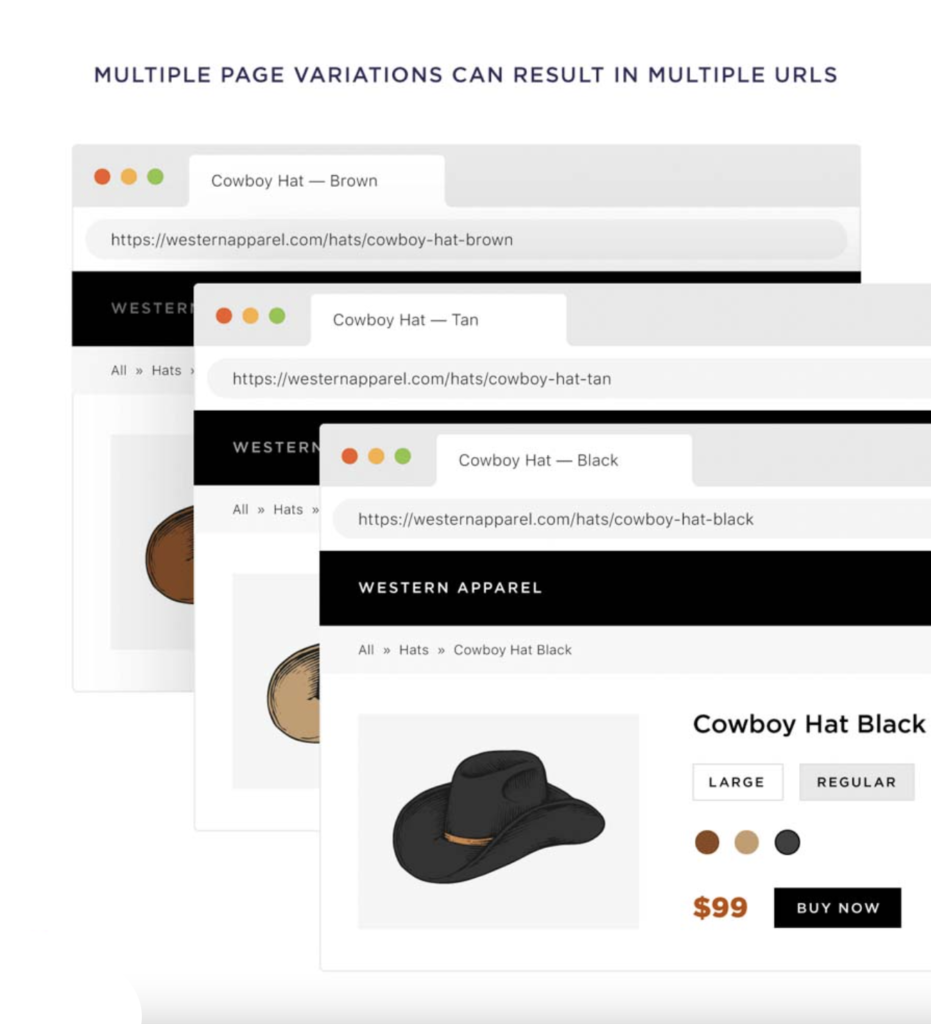
Depending on how the website is set up, any size, color, and variation can result in different URLs.
Luckily, you can use a canonical tag to tell Google that the vanilla version on a product page is the “major” version. All others are variations.
Page loading speed
Content to show:
Improving page loading speed will help optimize user experience
This content will show you 3 simple ways to speed up page loading:
Reduce Web page size
- CDN.
- Caching.
- Slow loading.
- Minify CSS.
I’m sure you’ve read about these approaches thousands of times before. But I don’t see a lot of people talking about important page speed factors like:
- Website size.
In fact, when Backlinko ran a large-scale page speed study, it was found that the total size of a page correlated with load time more than any other factor.
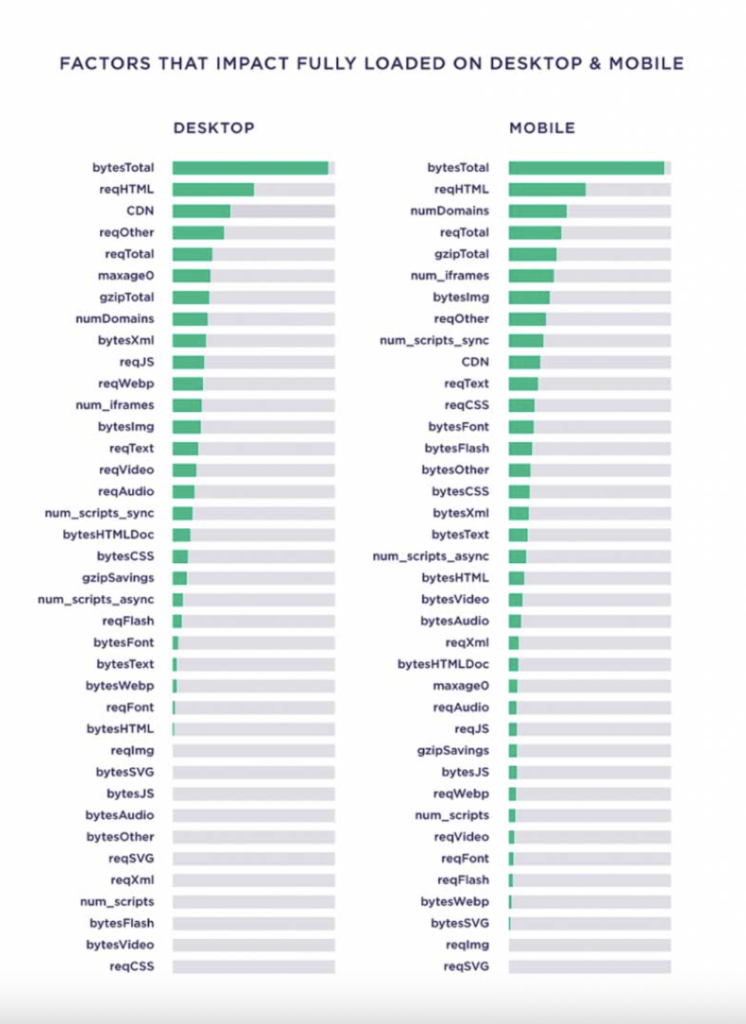
Lessons learned here are:
When it comes to page speed, there is no free lunch.
You can compress images and cache them from your website. But if the pages are very large, they will take a while to load.
This is something that a lot of great websites struggle with, like at Backlinko’s website. The images are heavily used, high resolution, the pages tend to be very large.
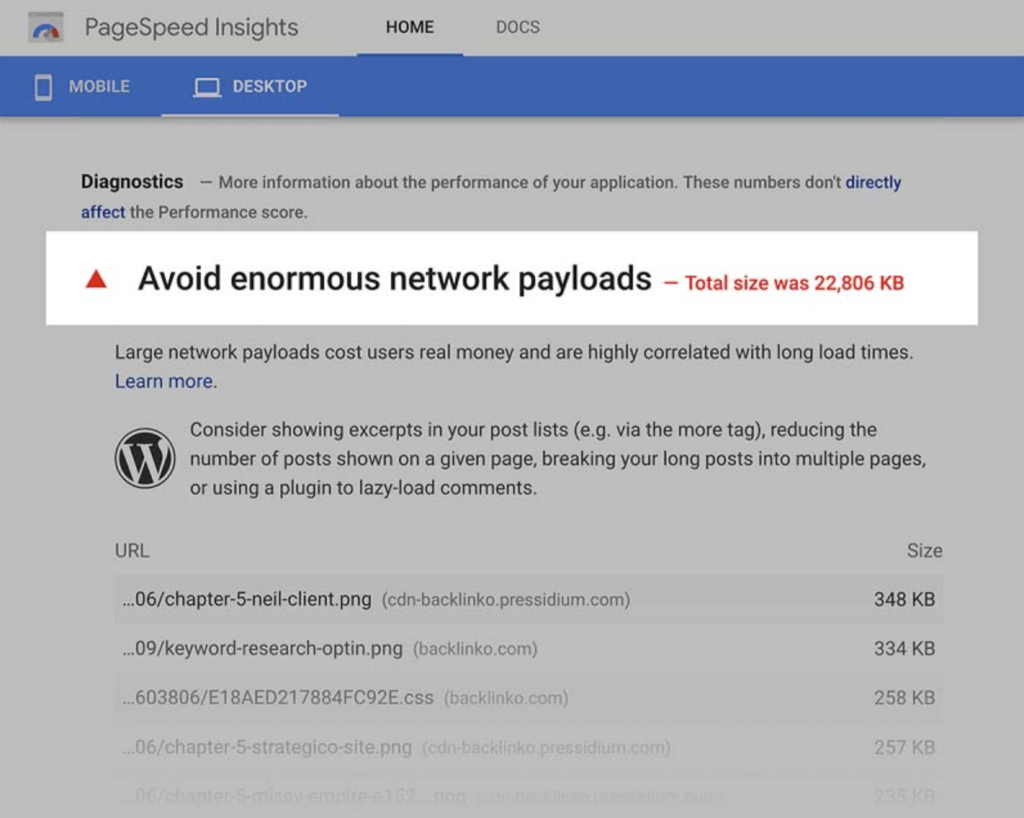
Check load times and CDN
Next, you may be surprised when I say: CDN is related to slow page load speed.
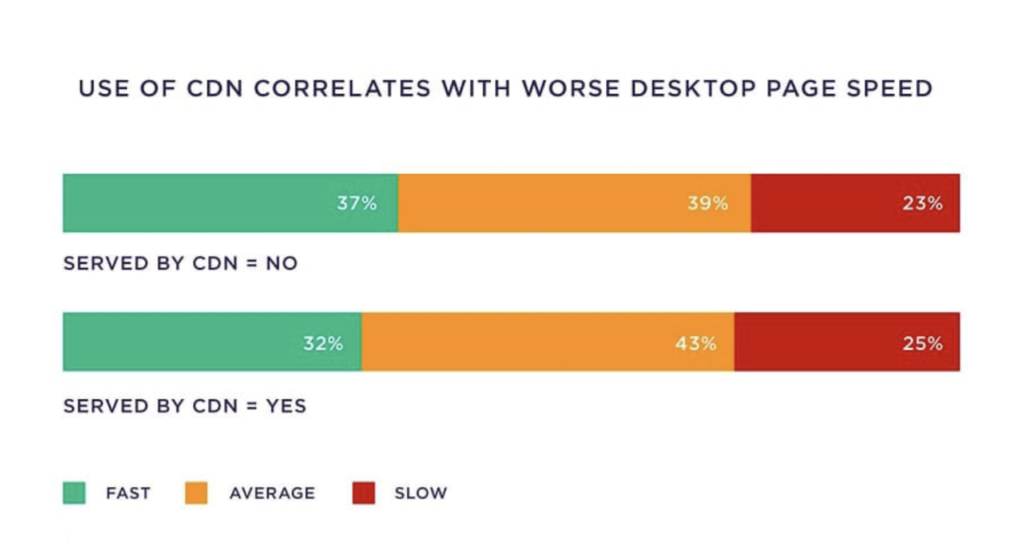
This could be because many CDNs are not set up properly. So, if your website uses a CDN, I recommend you to test your website speed on webpagetest.org or experte.com with CDN on or off.
Removed 3rd party script
Did you know: Every 3rd party script a page adds an average of 34 milliseconds to its load time.
So all you need to do is see which party scripts should be removed.
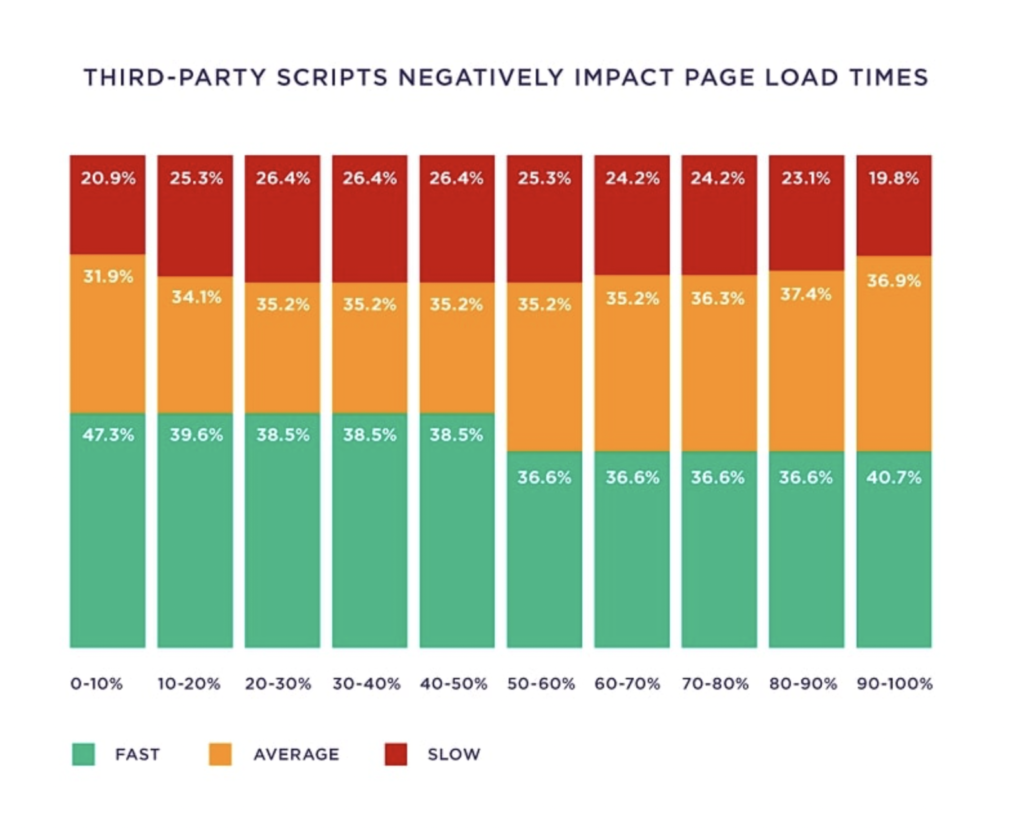
Tips: Standardize Technical SEO (2023)
Implement hreflang for International Websites.
Does your website have versions for different countries and languages?
If not, hreflang tag will be a GREAT assistant for you.
The only problem with the hreflang tag is: It’s hard to set up. And Google’s documentation on how to use it is not so clear.
So you can use Aleyda Solis’ Hreflang Generator.
This tool makes it (relatively) easy to generate Hreflang tags for multiple countries, languages, and regions.
Check the website for Dead Links
Having a bunch of Dead Links on your website won’t make or break SEO. In fact, Google even says that Dead Links are “ not an SEO problem ”.
But if you have broken internal links. That is another story.
Broken internal links can make it difficult for Googlebot to find and crawl pages on your website.
So I recommend doing a quarterly SEO Audit that includes fixing broken links. You can find broken links on your website using a variety of SEO-checking tools:
- SEMrush.
- Ahrefs.
- Or Screaming Frog.
You can check out my article about Best Local SEO Software Tools to Boost Rankings in 2023 For an in-deep review of these tools.
Setting up Structured Data
Have you ever wondered: does setting up Structured Data directly help website SEO?
Your answer would be: No.
In fact, studying search engine ranking factors found no correlation between Structured Data and first page rank.
Which says:
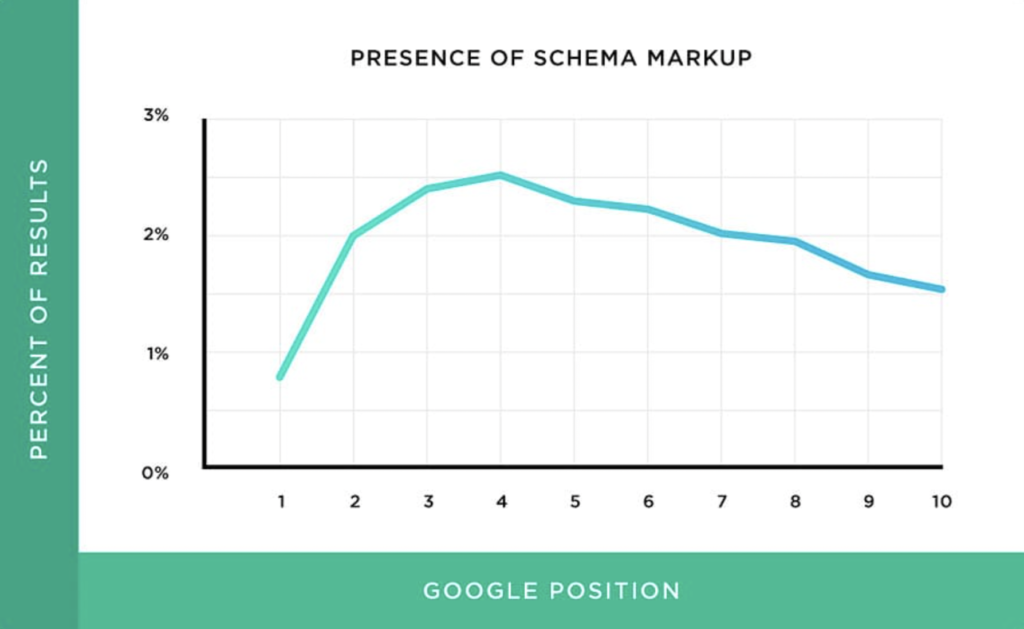
But, using Schema CAN give some pages Rich Snippets. Because Rich Snippets stand out in the SERPs, they can dramatically improve your organic click-through rate.
Validate XML Sitemaps (with content that links to XML Sitemaps)
If you run a large website, it can be difficult to keep track of all the pages in Sitemaps. In fact, many of the Sitemaps I look at have pages in 404 and 301 status. But this goes against my and your Sitemaps goal: to show search engines all active pages, want 100% of the links in Sitemaps to point to active pages.
So I recommend running Sitemaps through Map Broker XML Sitemap Validator. Just import Sitemaps from your website.
And see if there are any broken or redirected links.
Noindex Tag and Category Pages
If your website runs on WordPress, I highly recommend using noindex category and tag pages. (Unless those pages bring in a lot of traffic, of course). These pages often don’t bring much value to the user and they can cause duplicate content problems.
If you use Rankmath, you can easily prevent these pages from being indexed with just one click.
Expert Tips: In my experience, WordPress is the best platform for SEO. There are many WordPress development companies out there, but One Pixel Media is the right choice if You are looking for the Best WordPress Development and SEO Company.
Tested and optimized for mobile devices
Even super mobile-friendly websites can have problems. Unless users start emailing you complaints, these problems can be hard to spot. Therefore, to detect problems with your website, you should use the Google Search Console Mobile Usability report. If Google notices that a page on your website is not optimized for mobile users, it will let you know.
GSC even gives you the specifics of what went wrong in the page. That way, you’ll know exactly what needs fixing.
Bottom line
Now it’s your turn. These are all my tutorials on Technical SEO. Which of the tips I shared would you like to try?
Will you focus on speeding up your website?
Or maybe you want to find and fix deep links?
Either way, good luck!
Looking to boost your website’s search engine visibility and drive more traffic to your online business?
Look no further than One Pixel Media! Our expert SEO services are designed to help you achieve higher rankings on search engines like Google, Bing, and Yahoo, so you can attract more potential customers and increase your online revenue.
Don’t miss out on the opportunity to take your website to the next level – Contact us today and let’s get started!
UP NEXT:
- What is SEO? Benefits of SEO & Skills every SEO Expert should have
- What is On-Page SEO? Guide to optimizing Onpage SEO in 2023
- What is Off-page SEO? Most Effective Off Page SEO Technique Guide